Recently I read an article by Gerdemann and Hulden (2012) in which they provide finite-state implementations for two Optimality Theory (OT) analyses1 together with an easy proof of nonregularity of OT grammars.
This post is an annotated walkthrough of their OT implementation for word-final obstruent devoicing (e.g., German /lob/ > [loːp]), a phonological process that is observed in typologically diverse languages, which makes it a prototypical showcase for the universal constraints proposed by OT.
For their implementation, they use the finite-state toolkit foma(Hulden, 2009).
I will introduce necessary notation informally as it comes up, the following table only lists foma's deviations from the POSIX regex standard:
Notation
Description
~A
Complement
?
Any symbol in the alphabet
%
Escape symbol
[]
Grouping brackets
()
Parentheses surround optional parts
Generator
The Generator Gen implemented for this analysis describes all possible deletions (elisions), insertions (epentheses), and substitutions.
To keep track of each modification, "every surface segment (output) is surrounded by brackets [...], every input segment that was manipulated by Gen is surrounded by parantheses (...)", so we have four basic cases:
[a]: identity (input a, output a),
(a)[]: deletion (input a, output empty),
()[a]: insertion (input empty, output a), and
(a)[b]: substitution (input a, output b).
The following piece of code compiles a regular expression into a finite-state transducer (FST) that can be accessed later as Gen.
Gen = S -> %( ... %) %[ (S) %] ,,
S -> %[ ... %] ,,
[..] (->) [%( %) %[ S %]]* ;
The regex consists of three parallel rules delimited by ,,.
Each rule rewrites its left-hand side (before the arrow ->) into its right-hand side.
The symbol S is a variable for a transducer.
We can think of it as the set of available segments.
For the examples from the paper, this could simply be
S = [p|t|k|b|d|g|a|e|i|o|u];
The first rule creates all possible deletions and substitutions.
The three dots ... are a backreference to the input.
If S is the set of available segments, for a single input segment we get |S| + 1 outputs, one for each segment and one with empty square brackets.
The second rule just adds square brackets around its input (identity case).
The third rule produces an infinite number of insertions.
Square brackets with two dots [..] denote an empty left-hand side (nothing is replaced by something).
Generator automaton as defined by the three rules above.
Constraints
Now that we have an infinite number of candidates, we need to define our ranked set of constraints to evaluate them.
Here I just copy the definitions from the paper:
*VF: a markedness constraint that disallows final voiced obstruents.
IdentV: a faithfulness constraint that militates against change in voicing.
VOP: a markedness constraint against voiced obstruents in general.
The first constraint (*VF) obviously is responsible for the devoicing of final obstruents.
The second constraint (IdentV), ranked lower than the first, rules out unnecessary substitutions.
VOP never decides the race since it's ranked lower than the faithfulness contraint IdentV.
If we were only dealing with candidates that are minimal pairs such as *bed and bet (where /bed/ is the underlying form), the three constraints above would suffice.
However, Gen produces all possible insertions, deletions and substitutions, so we need additional faithfulness constraints to rule out forms such as *bede (epenthesis), *be (deletion), and *bek (substitution changing voicedness and place of articulation).
These incorrect forms are avoided with the following three constraints:
Dep: a faithfulness constraint against epenthesis.
Max: a faithfulness constraint against deletion.
IdentPl: a faithfulness constraint against changes in place of articulation of segments.
On page 14 in the paper, all six constraints are shown in action in an OT tableau.
Let's move on to the FST implementation.
The authors define two helpful templates for matching the context of constraint violations.
def Change(X,Y) [%( X %) %[ Y %]];
def Surf(X) [X .o. [0:%[ ? 0:%]]*].l/
[ %( (S) %) | %[ %] ];
The first template generates a simple substitution (X)[Y].
The second definition is more complex, we'll work through it from the inside out:
[0:%[ ? 0:%]]*: We have an arbitrary segment around which we insert square brackets. This pattern optionally repeats any number of times.
X .o. [0:%[ ? 0:%]]*: Compose the previous transducer with an expression that is the parameter of the Surf template. So the output language is the output of X with each segment enclosed in square brackets.
[X .o. [0:%[ ? 0:%]]*].l: Extract the range of the previous transducer (the output or surface language). The automaton generated from this expression accepts a word w if an input exists for which X .o. [0:%[ ? 0:%]]* produces w.
[ %( (S) %) | %[ %] ]: Generate the language that consists of single segments enclosed in parentheses, empty parentheses and empty square brackets.
[X .o. [0:%[ ? 0:%]]*].l / [ %( (S) %) | %[ %] ]: The pattern after the slash is optionally interspersed at any place any number of times within each word of the language described by the first pattern. If we use this pattern to recognize words, we can say that the pattern after the slash is ignored. For example: a+/b is equivalent to b*a+[a|b]*, or a+ after removing all instances of b.
So Surf(X) accepts all possible surface forms of expression X (and many invalid forms, but this is unproblematic because Gen does not produce them).
Furthermore, the authors define four segment subgroups: vowels (V), voiced consonants (CVOI), voiced and unvoiced phones.
With these groups and the Change template, they define regular expressions to recognize surface forms of two phonological processes: change of voice (VC) and change of place of articulation (Place).
The language of the first expression contains words such as (b)[p], replacements of a voiced obstruent with its unvoiced counterpart, or (k)[a], replacements of a voiceless obstruent with a vowel.
The second expression generates substitutions such as (p)[k], (i)[b] etc., but not (p)[b] or (d)[t], where the place of articulation is the same.
These intermediate expressions are now used to define the preceding context of the following four replacement rules that are constrained by context, more specifically A -> B || L _ R only applies if L precedes A and R follows A in the input (all other input passes unchanged).
VF inserts an asterisk after any surface form of a voiced consonant before a word boundary.
IdentV stars surface forms that indicate a change of voice.
VOP is a more general version of VF that doesn't require a word boundary.
IdentPl stars surface forms that indicate a change of place.
Finally the constraints forbidding insertion (Dep) and deletion (Max) are easy to implement.
In the former case we star empty parantheses, in the latter empty square brackets.
Dep = [..] -> {*} || %( %) _ ;
Max = [..] -> {*} || %[ %] _ ;
Evaluation
The final part of any OT analysis is Eval, the evaluation of the hierarchically ranked constraints.
We move from the highest ranked constraint to the lowest ranked, at each step eliminating all but those candidates that incur the minimal number of violations.
To do this we need a finite-state method of computing the set of candidates that have the minimal number of violations.
Counting doesn't seem like a viable solution, since we want an automaton with a finite set of states and we are dealing with an infinite number of inputs of unknown length.
The authors use a clever trick that they call worsening to solve this problem.
They define a transducer that adds any number of violations (stars) in any possible position to each candidate.
AddViol = [?* 0:%* ?*]+;
If you compose the inverse of this transducer with a constraint that adds violations to candidates, it will filter out all candidates with a non-minimal number of violations.
Let's look at a simple example.
We have a set of two candidates S1 = {a*, a***} and want to retain the candidate with the minimal number of stars (in this case * is a literal symbol, not a Kleene star).
Applying AddViol to S1 generates the language S2 that consists of all words with a single a and at least two stars.
Now we intersect S1 with the complement of S2 (assuming the universe is any string over our two-symbol alphabet), which gives us S1∩ S2c = {a*}, the subset of words in S1 with the minimal number of stars.
I glossed over one little complication of the worsening approach: the candidates to which we add stars differ from each other not only by the number of stars.
So if we have a candidate (t)[d] without any star and a second candidate (t)[]* with one star, we can add as many stars to the first candidate as we want, it will never match the second (nor will any other candidate).
The authors solve this by composing the inverse Gen with Gen (ignoring any stars) and adding violations to every possible configuration afterwards.2
Worsen = [Gen.i .o. Gen]/%* .o. AddViol;
For (t)[d] the inverse generator Gen.i outputs t, for which Gen produces [t], (t)[], (t)[d], and so on.
AddViol then produces starred variations, one of which will be (t)[]*.
So to filter out candidates with a non-minimal number of violations, we compose the previous transducer with the extracted range of its worsened complement.
After this step, we remove all stars because each candidate will have the same number and we don't need them for the evaluation of the next constraint.
def Eval(X) X .o. ~[X .o. Worsen].l .o. %* -> 0;
The output of this evaluation will be the input for the evaluation of the next constraint etc.
After all evaluations have been performed, remaining markup is removed with the Cleanup transducer.
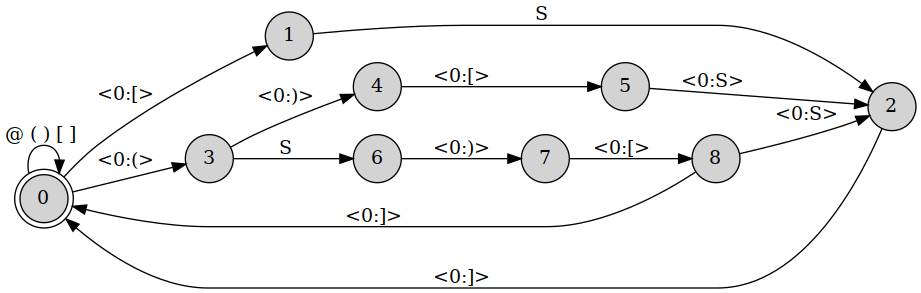
S+ restricts the input to non-empty strings over the segments defined above. After compiling the whole grammar, foma outputs this nice graphical representation via the view command.
FST for final obstruent devoicing analysis in OT.
Rule-based implementation
Instead of the OT analysis, we can translate the classical phonological rewrite rules directly into a transducer.
(Three replacements that apply in the same context.)
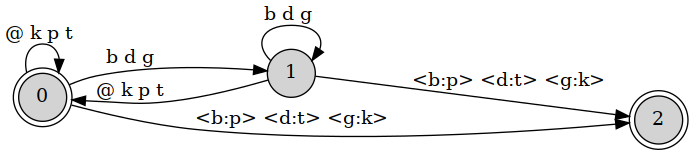
Rule = b -> p, d -> t, g -> k || _ .#. ;
RuleGrammar S+ .o. Rule;
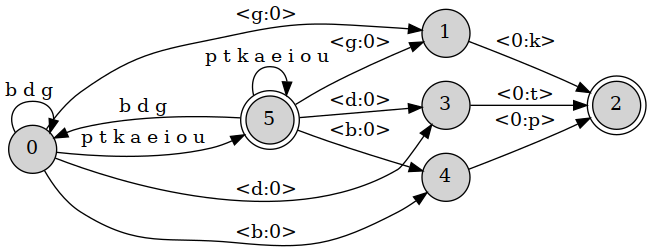
This transducer is weakly equivalent to the OT transducer (produces the same language), but is structurally different, as can be seen from its graphical representation.
FST for final obstruent devoicing from phonological rules.
Because both the OT transducer and the rule transducer represent a function, we can test for their equivalence: (1) they apply to the same domain, and (2) the composition of the inverse of one with the other is an identity transducer.
From an engineering point of view, the OT analysis doesn't seem appealing compared to the classical rewrite rules.
We need many definitions that are far more complex, the resulting automaton is more complex, and for some OT grammars, a finite-state implementation is impossible.
Theoretical linguists on the other hand usually don't care too much about the computational complexity of their analyses and frameworks, for them OT is appealing because it allows them to trace certain properties of languages back to universal constraints rooted in articulation and perception (in the case of phonology).
Still it seems to me that linguists could profit from implementing their analyses with finite-state technology.
Implementing a functional transducer forces us to turn implicit assumptions into explicit constraints. We have seen this with the extra set of faithfulness constraints that were necessary to avoid suboptimal forms.
The computer can help ensuring that the analysis is correct and works as intended.
We can write automated tests for input-output pairs.
If we have a rule-based equivalent as above, we can check for correctness algorithmically.
Once we have a working FST implementation, we can use it in both directions, that is, we can transform an underlying form into a surface form, or generate possible underlying forms for a given surface form.
2 In general, violations do not necessarily line up. For these cases the authors introduce a violation-permuting transducer that needs to be applied the right number of times. However, this problem does not affect the devoicing analysis, so I ignore it here.
Gerdemann, D., & Hulden, M. (2012). Practical finite state optimality theory. In Proceedings of the 10th International Workshop on Finite State Methods and Natural Language Processing (pp. 10-19).