Effect of sentence length on language identification accuracy
At the end of last semester I gave a student who just started programming the task of implementing two basic language identification algorithms, one identifies the language of a text based on the most frequent words, the other one based on character frequencies. Here I briefly present my own solution in Python and evaluate both methods.
We don't need to reinvent the wheel, so let's use some well-known libraries:
import os
import re
from collections import Counter, OrderedDict
import numpy as np
from scipy.spatial import distance
For training and testing, we'll use a subset of the Europarl corpus (Koehn 2005): ten documents per language (Danish, Dutch, English, Finnish, French, German, Italian, Portuguese, Spanish and Swedisch) for training and 1,000 randomly sampled sentences per language (with at least 20 characters) for testing.
The files are encoded in ISO-8859-1. To get the plain text, we need to remove some mark-up with a short regex.
def read_text(path):
with open(path, encoding='iso-8859-1') as fin:
return re.sub(r'<.+?>', '', fin.read())
The directory tree of the corpus is simple: under the root we have one directory per language containing a flat list of text files. To keep path operations separate from the algorithms, I use two generator functions. (Language codes are sorted lexicographically for reproducible results, see below.)
def iterate_corpus(corpus_root):
for language in sorted(os.listdir(corpus_root)):
yield language, iterate_paths(os.path.join(corpus_root, language))
def iterate_paths(root):
for name in os.listdir(root):
yield os.path.join(root, name)
During training, the first method counts the frequency of all words (or more precisely tokens, in this case defined as a sequence of alphanumeric characters) and remembers the ten most frequent words for each language. At prediction time, we compute pairwise intersections between the set of tokens of the given text and the set of tokens for each language. The language with the largest intersection wins.
class StopwordLanguageId:
WORD = re.compile(r'\w+')
def __init__(self, corpus_root):
self.words_by_lang = self._collect_words(corpus_root)
@classmethod
def _collect_words(cls, corpus_root):
words_by_lang = OrderedDict()
for language, paths in iterate_corpus(corpus_root):
c = Counter()
for path in paths:
c.update(cls._tokenize(read_text(path)))
words_by_lang[language] = set([w for w, _ in c.most_common(10)])
return words_by_lang
@classmethod
def _tokenize(cls, text):
for token_match in cls.WORD.finditer(text):
yield token_match.group(0).lower()
def identify_language(self, text):
tokens = set(self._tokenize(text))
scores = [(lang, len(tokens.intersection(ws)))
for lang, ws in self.words_by_lang.items()]
return max(scores, key=lambda x: x[1])[0]
For multiple maximal items, Python's max function returns the first.
To get reproducible results, we use an ordered dictionary to which keys are added in lexicographical order of the language codes.
The second method counts how often each character occurs in each language of the training corpus. Since our corpus uses an 8-bit single byte encoding, we can use a 256-element list to collect the frequencies (considering only printable characters, we could do with less, but we'll keep the code short and simple). At prediction time, we compute a 256-element frequency vector for the characters in the given text and compute the cosine distance between this vector and each language's character frequency vector. We predict the language with minimal cosine distance.
class CharLanguageId:
def __init__(self, corpus_root):
self.frequencies, self.languages = self._collect_frequencies(corpus_root)
@classmethod
def _collect_frequencies(cls, corpus_root):
freqs, langs = [], []
for language, paths in iterate_corpus(corpus_root):
freq = [0] * 256
for path in paths:
cls._count_chars(freq, read_text(path))
freqs.append(freq)
langs.append(language)
return np.array(freqs), langs
@staticmethod
def _count_chars(freq, text):
for char in text:
freq[ord(char)] += 1
return freq
def identify_language(self, text):
text_freqs = np.array(self._count_chars([0] * 256, text)).reshape(1, -1)
dists = distance.cdist(self.frequencies, text_freqs, 'cosine')
return self.languages[np.argmin(dists, axis=0)[0]]
For the evaluation I randomly sampled 1,000 sentences per language with a length of at least 20 characters from the same corpus (excluding documents used for training). So which method works better?
The word-based approach classifies 9,478 out of 10,000 sentences correctly, the character-based approach only 9,271. The overall difference between both results is only about 2%, however, the mistakes are quite different in nature. Looking at the confusion matrix for the character-based approach, we observe some interesting patterns (actual (A) against predicted (P) language codes, top-ten off-diagonal entries in bold):
| A\P | da | de | en | es | fi | fr | it | nl | pt | sv |
|---|---|---|---|---|---|---|---|---|---|---|
| da | 915 | 15 | 5 | 2 | 2 | 0 | 3 | 10 | 8 | 40 |
| de | 12 | 932 | 3 | 3 | 4 | 9 | 4 | 13 | 2 | 18 |
| en | 2 | 4 | 921 | 9 | 5 | 6 | 21 | 21 | 7 | 4 |
| es | 1 | 6 | 0 | 878 | 0 | 19 | 23 | 5 | 61 | 7 |
| fi | 0 | 2 | 3 | 3 | 983 | 0 | 3 | 3 | 2 | 1 |
| fr | 3 | 6 | 4 | 16 | 13 | 902 | 22 | 11 | 21 | 2 |
| it | 1 | 2 | 6 | 36 | 2 | 9 | 913 | 13 | 15 | 3 |
| nl | 17 | 11 | 5 | 7 | 3 | 1 | 5 | 936 | 3 | 12 |
| pt | 1 | 1 | 5 | 29 | 0 | 8 | 12 | 9 | 933 | 2 |
| sv | 14 | 1 | 1 | 1 | 9 | 1 | 5 | 9 | 1 | 958 |
Most mistakes are confusions between Spanish, French, Italian and Portuguese – four Romance languages, another group that seems to be close is Danish, German, Dutch and Swedish – four Germanic languages. Character frequencies work best for Finnish, at least in our selection of languages, where Finnish is the only representative of the Finno-Ugric family of languages. Apparently our simple character frequencies give us a primitive measure of 'closeness' between languages.
The confusion matrix for the most-frequent words method looks very different and is less interesting from a linguistic point of view.
| A\P | da | de | en | es | fi | fr | it | nl | pt | sv |
|---|---|---|---|---|---|---|---|---|---|---|
| da | 992 | 3 | 0 | 0 | 0 | 1 | 0 | 0 | 0 | 4 |
| de | 30 | 967 | 0 | 0 | 0 | 2 | 1 | 0 | 0 | 0 |
| en | 36 | 2 | 961 | 0 | 1 | 0 | 0 | 0 | 0 | 0 |
| es | 28 | 0 | 2 | 969 | 0 | 0 | 1 | 0 | 0 | 0 |
| fi | 72 | 1 | 2 | 2 | 922 | 0 | 0 | 0 | 1 | 0 |
| fr | 41 | 0 | 0 | 40 | 0 | 915 | 4 | 0 | 0 | 0 |
| it | 26 | 2 | 6 | 29 | 1 | 15 | 917 | 0 | 1 | 3 |
| nl | 42 | 0 | 0 | 0 | 0 | 0 | 1 | 954 | 3 | 0 |
| pt | 28 | 1 | 13 | 22 | 0 | 3 | 3 | 0 | 930 | 0 |
| sv | 44 | 4 | 0 | 0 | 0 | 0 | 0 | 1 | 0 | 951 |
Most wrong predictions are in the first column (Danish), almost all confusions are below the main diagonal of the matrix. The distribution we see here is mostly an artifact of our tie-breaking strategy: if the text to be classified does not contain any of the previously collected most frequent words, we have a trivial tie between all available languages and the algorithm predicts the first element from our list of lexicographically sorted ISO 639-1 codes (da). In general, if we have a tie between a group of languages, the language whose ISO code appears first in the alphabet is predicted, e.g. Spanish (es) vs. French (fr) or Italian (it).
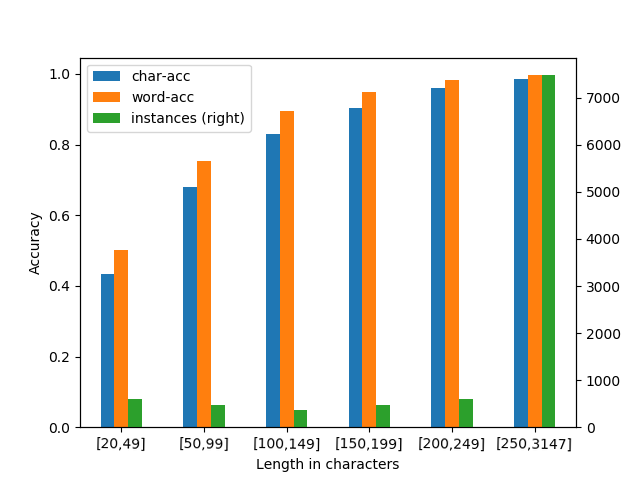
Lastly, let's have a look at the influence of text length on accuracy.
In the following diagram, the accuracy of both models (blue and orange bars) is plotted for different text lengths in characters.
Text lengths are binned into 50-character intervals (except for the first interval, which is shorter, and the last interval, which is much longer).
The green bars indicate the number of test instances per bin.
Effect of sentence length on language identification accuracy
The plot shows similar accuracy distributions for both methods and reveals one big weakness: for short texts accuracy is low. The reason for the high overall accuracy is the length distribution of the test data: the overwhelming majority of test instances is more than 250 characters long.
Philipp Koehn (2005). Europarl: A Parallel Corpus for Statistical Machine Translation, MT Summit 2005.
This page was moved from my old website.